
Data
This is a massive topic but the intention here is to cover a few topics, setting the scene, best practice and advising on a few actions that will set up for success shift the needle But first setting out what is meant by:
o 1st party - highly values and accurate data that is sourced directly from your own systems, e.g. customer transactions, prospect enquiries, website activity, email engagement, support centre contact, direct customer reviews, opt-in permission.
o 2nd party - your customer data taken from trusted partners so needs permission to be shared, e.g. google traffic, external product reviews.
o 3rd party - less distinct aggregated data appended to each customer, e.g. geodemographics, weather, facebook results.
o Macro - high level data at a regional or national level, e.g. competitor activity, market share, macro economics.
Data Quality: Value & Use
[Stand]
The real world is not like the CSI tv show, which seem to have a handy database to access that will break the case. Ironic but a truth, that the most useful data is either illegal, not given up by people, not collected, proprietary or expensive. Data used by accountants and supply chains tend to be reasonably complete but customer and intent data less so.
The key is understanding what the data will be used for, and that any limitations around it will not prevent this from happening.
Data Quality: Collection & Ingestion [Stand]
Controlling the data that enters the database is vital. Issues that need to be spotted and put in a data load report:
o Words being in number fields.
o Difference between a zero and a blank. Blank is no information and Zero is a value. Need to rip out any Blank fields that have.
o Creating new (custom) fields where fields already exist.
o Duplicates Type 1 – duplicates within the file about to go into the d-base.
o Most of the issues in loading data is complicated by duplicates, i.e. a high unique v duplicate ratio should be ring-fenced and not allowed into the d-base core until understood.
What automatic warnings have you got in place at the interfaces to alert partial or completely failed loads? Don't be the last to find out.
What fix-on-fail or SLAs with suppliers can you lean on?
Suppressions
[Stand]
For many reasons some customer data must be removed, masked at different point of the process. Suppressions are comprehensive or partial depending on their use and where they sit in the data cascade.
There are 3 main buckets:
o Personal information (PI), can include PII but also includes anything you did like sales or question without identifying you. Customer PII is autonomised if they have not had a positive proactive integration with the data owner in the last 7 years.
o Personally identifiable information like (PII) is any data that can identify you like your name, contact details, home address, IP address.
o Sensitive information (SI) needs a higher level of care as it covers anything that could create discrimination - sexual orientation, religious beliefs, private health matters.
Exclusions are purposeful suppressions for marketing reasons can include:
o Purchase related: a new customer may be blocked from receiving marketing comms whilst in an onboarding program or have returned their product. Other reasons could be if they are exchanging or repairing their purchase.
o Channel related: Permission fields must be present. Under certain documented methods implied permission can be used. Company employees, other test data, hard bounces, 3 soft bounces and old email domains are usually excluded.
o Customer stimulated: includes those who have unsubscribed from certain comms/channels. Also can include people who complain or have requested a GDPR DSAR.
o Strategy defined: perhaps a fallow test cell to compare macro long term tests.
o Deduplication checks: removes or merges using the matchkey of the channel’s primary contact field.
Data Quality: Privacy
[Stand]
The system and pipelines needs to pass security checks. Legal and Privacy will have lots of paperwork to be done on any new dataset, processing or use. Laws change depending which country you are in but GDPR is a good standard to start with.
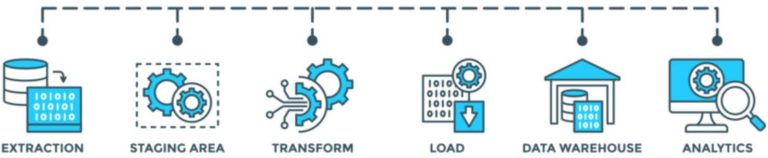
Data Quality: ETL
[Walk]
Every company I've talked with or worked for over the last decade is very aware that their current system is either creaking at the seams, suffering growing pains, not real-time enough or cannot work with the new cloud big data platforms. Welcome to the speed of change and its not slowing down.
You need a Data Strategist, Data Architect, Full-stack developer coming together. Not just understand what you want to build, or ensure that what you get is actually what you need for the next decade, but also how to zig-zag between the many deliverables to cut-over to the new capabilities whilst ensuring business doesn't slow down or stop.
Be warned, it's expensive and a long term commitment so understand what you will get, what you won't and ensure you have your own expert in the room when you talk to suppliers to point out any over-selling.
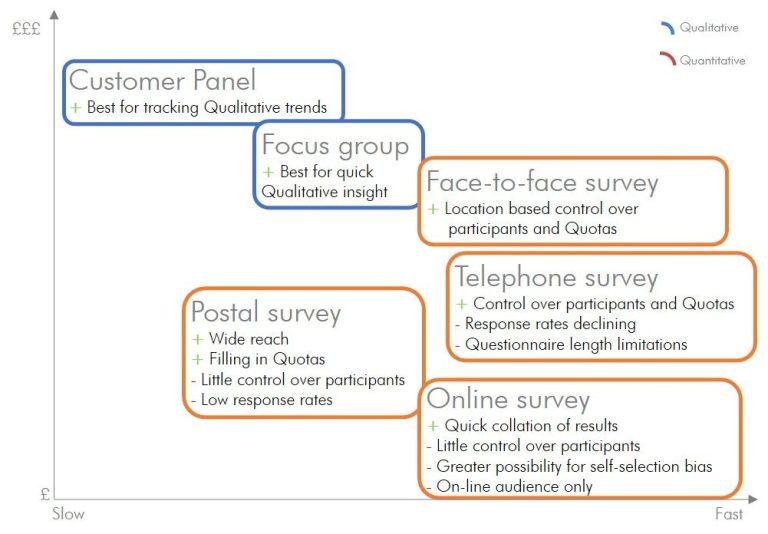
Market Research: Qualitative
[Stand]
Qualitative provides a more complete picture of an issue or problem and how customers or prospects are thinking about it:
o Explores ideas, perceptions and behaviours in depth.
o Uses a small number of participants.
o Used complex open-ended questions.
o Data may not be easily tabulated or translated into percentages.
o Provides directional information.
o Answers could be subjective of idiosyncratic.
o Helps marketeers understand the bigger picture.
Campaign Analysis: BI
[Stand]
Method a KPIs are overed in the 'Business Information & Measuring' page.
The key is ensuring that the definitions of success in terms of KPI and any context is written down before a campaign begins - to make campaign reporting and washup more effective.
Market Research: Quantitative [Stand]
Quantitative provides more specificity about what proportion of the population shares common preferences, beliefs, or behaviours:
o Used when needing to quantify who believes or acts in a certain way.
o Large data sets providing statistically valid results.
o Closed, simple or multiple-choice questions.
o Easily counted, tabulated and statistically analysed.
o Test and control results.
o Answers can be statistically tested.
o Provides detail and dimensions.
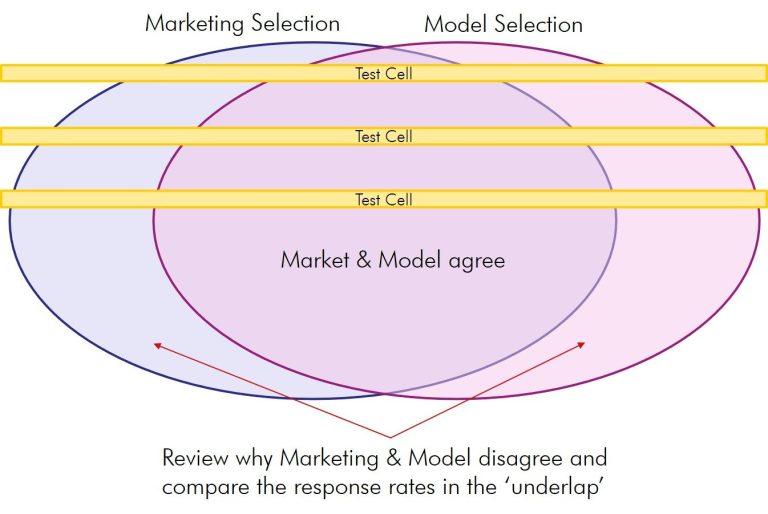
Campaign Analysis: Tests
[Stand]
Set up is covered in the 'Test & Learning Loops' page.
A simple test is better than none. The 6 Dimensions are set up so that each should not trip over a test in another. Too many tests in one campaign will diminish the results which will probably not make them invalid but will change the statistical method.
The rule of thumb is, everything else being equal, the first of two cells to reach 40 responses is the winner. Don't fall into the common mistake of thinking the test cell needs to be a percentage of the population - it doesn't. It has to be larger than a certain number, and that number is whatever will give about 50 responses.
Setting up the test properly is key, check with someone who understands statistics as it's common to have a bias, sometimes accidentally but usually deliberately, which will cost in the long term.
The reality is that the differences are small and reside in the edges of the Venn diagram, as Marketing and Model will select similar populations. The exam question is 'who did they select differently, how did they react and why.'
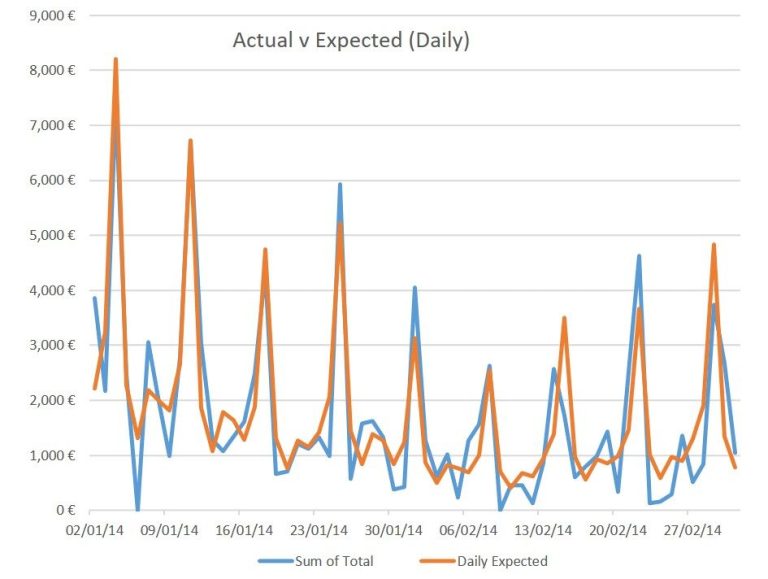
Campaign Analysis: Deep Dives [Walk]
Deep dive insight reports are the lifeblood of strategic decision making and needs a data analyst who will understand the nuances of the exam questions and how to tell a narrative. Use the Triage part of this website to spec out the critical dimensions and criteria - don't be vague in a spec.
It's not easy to distill so many considerations and datasets into a concise and informative summary. A picture is indeed worth 1000 words but answers to complex questions usually needs more than a 2 dimensional graph. The recipient needs to invest in developing the exam question with the analyst and then the patience to listen, consider and interpret the 'so what' answer together. Both should expect that there will another iteration to refine the question/answer as the critical factors get uncovered. As these reports are not quick they should be used for informing future strategic options, not forced to support already made decisions.
I advise limiting the plethora of caveats, start from the 'single version of the truth' already socialised and consider the data outcome could be a new KPI which solely describes and tracks this strategic vector.
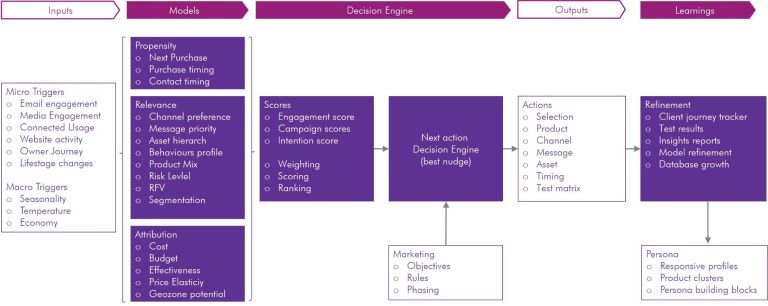
Decision Engine
[Run]
The task of a data-led marketing and optimisation Decision Engine is to constantly calculate, select, push, monitor, report, learn, refine those always-on and trigger marketing campaigns - combining all the What, Who, Why, How, When, Where prescriptive and reactive aspects of the marketing programs. The goals and controls are inputted by KPI targets ranges by priority. The outcome of these KPIs can be pre-viewed by scenario running via the same engine. This releases employees to focus on topics that big data/maths cannot do better.
At the heart of any complex system are mathematic decisions. The zeitgeist has called this many things, most recently data science (MLOps) or AI. But these are just tools and can easily misfire because they miss the vital connection to the humanistic aspects of the inputs and outputs.
The best decision engines are designed by balancing 2 conflicting realities:
o What input data is available? Its wrong to assume that the data needed is available, and if it is, it'll probably have issues around forced infilling
o What outputs are wanted? Its wrong to assume that whatever the data is available will provide the required outputs.
Put a humanistic lens onto this and both will flex to make a usable Decision Engine, i.e. what is the key choice made in the activation platform and how is this informed and measured? What is the completeness of the most powerful data in the model and can this be broken down into more available but less sophisticated insight that won't diminish the model that much?
Decision Engine: Core Maths
There's lot of different techniques inside big-data and may get around to blogging more details but the incomplete list includes:
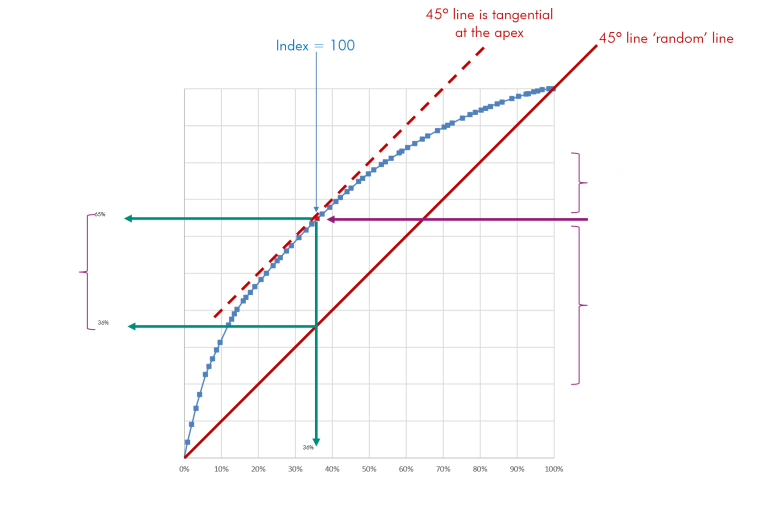
o Gains curve (pictured) is concerned with optimisation of limited resource against strategy. A similarity shaped Receiver Operating Characteristic (ROC) curve is a way to compare models. This shape is the power house of most Marketing Science maths, and originates from the 17th century calculus maths.
o Poisson curve expresses the probability of a given number of events occurring in a fixed interval of time. This math originated in the 18th century.
o Time series methods can unpick cause/effect factors to extract the meaningful characteristics from short (hour, day) to long periods (season, years).
o Step change detention can determine if an outlier is the start of a new and definitive jump in results.
o Infilling is required where missing data is limiting the application of decisions. Incorrect, forcing or overfilling produce a self-perpetuating effect error.
o Correlation, Clustering, Power. Different methods doing different things but all are understand the extent connections between variables, data points and the accepted truth.
o Matchkeys connect data and can be in parallel or in series to define the most effective method of linking large datasets whilst removing the risk of incorrect associations.
o Standard Error, Skew, Kurtosis, Standard Deviation exam the outputs to control and curtain any unusual results or outliers .
© Copyright. All rights reserved.
We need your consent to load the translations
We use a third-party service to translate the website content that may collect data about your activity. Please review the details in the privacy policy and accept the service to view the translations.